
评测简介
近年来,随着以裁判文书为代表的司法大数据不断公开,以及自然语言处理技术的不断突破,如何将人工智能技术应用在司法领域,辅助司法工作者提升案件处理的效率和公正性,逐渐成为法律智能研究的热点。中国法律智能技术评测CAIL(Challenge of AI in Law)旨在为研究者提供交叉学科的学术交流平台,推动自然语言处理、智能信息检索等人工智能技术在法律领域的应用,共同促进中国法律智能技术的创新发展,为科技赋能社会治理作出贡献。
为了促进智能技术赋能司法,实现更高水平的数字正义,在最高人民法院和中国中文信息学会的指导下,从2018年起,CAIL已连续举办了六届中国法律智能技术评测,先后吸引了来自海内外高校、企业和组织的近5000支队伍参赛,成为中国法律智能技术评测的重要平台。CAIL 2018设置了罪名预测、法条推荐、刑期预测三个任务,并提供了包含268万刑事法律文书的数据集;CAIL 2019设置了阅读理解、要素识别、相似案例匹配三个任务;CAIL 2020设置了阅读理解、司法摘要、司法考试、论辩挖掘四个任务;CAIL 2021设置了阅读理解、类案检索、司法考试、司法摘要、论辩理解、案情标签预测、信息抽取七个任务;CAIL 2022设置了司法考试、事件检测、文书校对、类案检索、涉法舆情摘要、论辩理解、信息抽取、可解释类案匹配八个任务;CAIL 2023设置了司法考试、对话式类案检索、类案检索、事实认定、论辩理解、信息抽取、司法大模型七个任务。 随着智能技术与法律需求交叉融合的不断深入,CAIL的任务设置更加符合司法需求,任务难度也逐年升级。
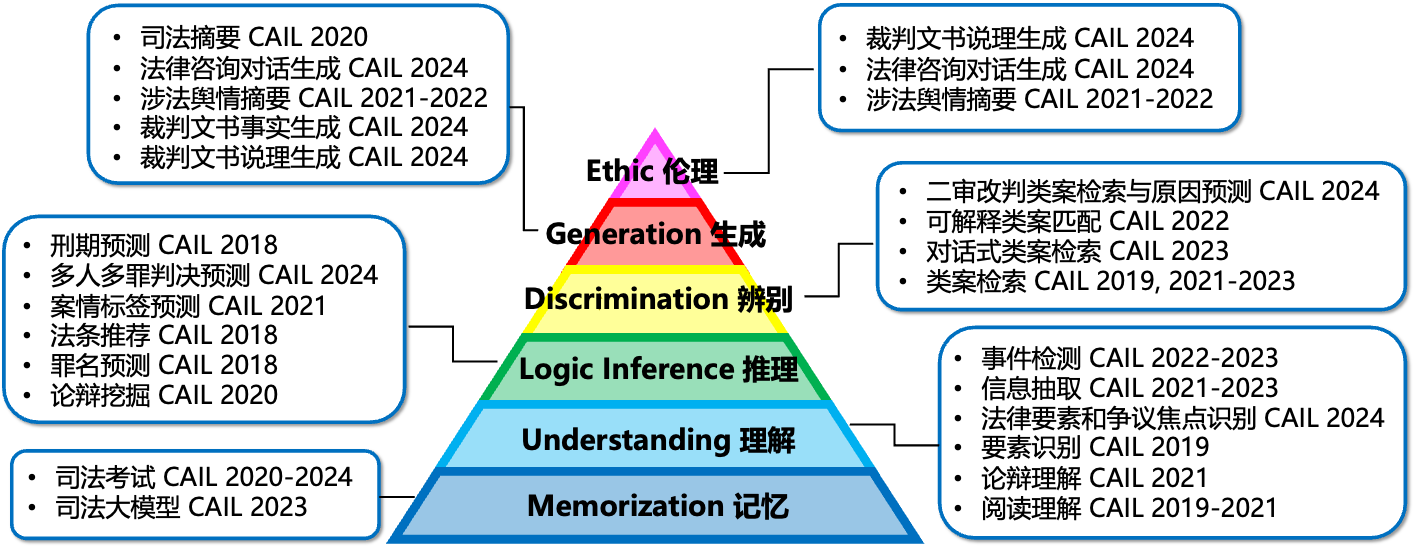
大型语言模型在自然语言处理任务中取得了显著进展,并在法律领域展现了相当大的潜力。然而,法律应用在准确性、可靠性和公平性方面都有非常高的要求。在未仔细评估其潜力和局限性的情况下,将现有的大模型应用于法律系统,可能会对法律实践带来重大风险。为此,我们构建了法律认知能力评估框架,将司法大模型应当具备的能力分为六个层次,包括:记忆层、理解层、推理层、辨别层、生成层、伦理层。记忆能力评测,是评估模型记忆法律信息的能力,包括法律概念,法律规则,法律演变等;理解能力评测,是评估模型理解法律含义及其影响的能力,包括法律要素识别,法律事实验证,阅读理解,关系抽取,命名实体识别;逻辑推理能力评测,是评估模型运用法律事实进行逻辑推理的能力,包括案由预测,法条预测,刑期预测,多跳推理,法律计算,争辩挖掘等;辨别能力评测,是评估模型分析和判断法律信息的价值的能力,包括类案辨别,文档修正等;生成能力评测,是评估模型撰写专业的法律文件和论证性文本的能力,包括摘要生成,裁判分析过程生成,法律翻译,开放式问答等;伦理评测,是评估模型判断法律中的伦理问题的能力,包括偏见与歧视,道德,隐私。有关法律认知评估框架和司法大模型评估的更多内容,请参见论文LexEval(https://arxiv.org/abs/2409.20288)。
CAIL 2024一共设置了八个任务,分别为:裁判文书事实生成、裁判文书说理生成、法律要素和争议焦点识别、二审改判类案检索与原因预测、法律咨询对话生成、司法客观题考试、多人多罪判决预测、司法主观题考试,同时将提供海量司法文书数据作为数据集。
CAIL 2024赛程为9月初至11月持续3个月时间,预计将于2024年12月在北京举办颁奖典礼暨法律智能技术研讨会。诚邀学术界和工业界的研究者和开发者积极参与和支持评测!
更多详细信息可以参考GitHub或者访问QQ群237633234了解。

扫描QQ二维码
最新动态
CAIL 2024 组织单位
指导单位
 中国中文信息学会
中国中文信息学会主办单位
 中国中文信息学会
中国中文信息学会 中国中文信息学会
中国中文信息学会 中国中文信息学会
中国中文信息学会 中国中文信息学会
中国中文信息学会承办单位
 清华大学
清华大学 清华大学
清华大学 清华大学
清华大学 清华大学
清华大学 南京大学
南京大学
 中国人民大学
中国人民大学 北京理工大学
北京理工大学 武汉大学
武汉大学


CAIL 2024 金牌赞助单位
 航天国政信息技术(北京)有限公司
航天国政信息技术(北京)有限公司 北京麦伽智能科技有限公司
北京麦伽智能科技有限公司 北京星川律政科技有限责任公司
北京星川律政科技有限责任公司CAIL 2024 银牌赞助单位
 阿里云计算有限公司
阿里云计算有限公司指导委员会
程序委员会
评测委员会
- 解惠媛
清华大学 - 叶宇潇
清华大学 - 刘 云
清华大学 - 毛佳昕
中国人民大学 - 公培元
中国人民大学 - 马晟杰
中国人民大学 - 吴之璟
北京理工大学 - 刘东硕
北京理工大学 - 孙敏豪
北京理工大学 - 冯 奕
南京大学 - 刘泽阳
山东大学 - 任鹏杰
山东大学 - 陈 哲
山东大学 - 张 帆
武汉大学 - 张文波
武汉大学 - 肖朝军
清华大学 - 刘布楼
清华大学 - 李海涛
清华大学 - 陈俊杰
清华大学 - 王志博
北京方圆众合教育科技有限公司 - 宋凯嵩
阿里巴巴通义实验室 - 梁永涛
航天国政信息技术(北京)有限公司 - 张 进
航天国政信息技术(北京)有限公司 - 杜 斟
航天国政信息技术(北京)有限公司 - 罗 成
北京麦伽智能科技有限公司 - 邹邵坤
北京星川律政科技有限责任公司